Robots.txt Nedir, Nasıl Oluşturulur?
Robots.txt Nedir?
Robots.txt, web site yöneticileri tarafından oluşturulan ve sitelerde tarama faliyetleri gerçekleştiren web robotlarının (Arama motoru botlarının) siteyi ne şekilde tarayacağının direktiflerle anlatıldığı txt formatındaki dosyanın adıdır. Robots.txt dosyasının içerisinde kullanılan belirli web direktifleri ile site yöneticisi web robotlarını sitesi dahilinde kontrol edebilir hale gelir.
Robots.txt kullanılarak istenmeyen botların site taraması engellenebilir veya ilgili botlar için site taramalara açılabilir. Sitenin barındırıldığı sunucu üzerinde sitenin hangi dosya yollarının taranıp hangi dosya yollarının taranmayacağı yada herhangi bir dosya yolu üzerinde hangi bölüme kadar tarama yapılıp hangi bölümlerin es geçileceği gibi çok detaylı tarama direktifleri robots.txt üzerinden sağlanabilir.
Web robotlarının kılavuz dosyası olarak adlandırabileceğimiz bu dosya arama motoru botlarının bir site içerisinde ilk göz attığı yer olarak karşımıza çıkar. Site içerisinde robots.txt dosyası bulunmayan veya sağlıklı düzenlememiş siteler kapsam hatalarıyla, indekslenmeyen sayfalar ile veya arama motorlarında yavaş indeks alma, kısıtlı (başarısız) inkdeslenme süreçleriyle karşılaşırlar.
WordPress kullanan siteler için robots.txt dosyasını oluşturmak görece diğer web sitelerine göre daha kolaydır. Yoast SEO eklentisini kullanarak tek tıklama ile normal çalışan bir robots.txt dosyası oluşturabilirsiniz.
Robots.txt Dosyası Nerede Bulunur?
Robots.txt dosyası web sitelerinin ana dizininde (public_html, httpdocs vb) sabit olarak bulunur. Burada sitenizi yeni oluşturduysanız ve robots.txt dosyanız mevcut değil ise bilgisayarınızda herhangi bir txt dosyası oluşturup aşağıda detaylıca örneklerini verdiğimiz robots.txt yapılarına bağlı kalarak, bir robots.txt dosyası oluşturabilir ve sitenizin ana dizinine kaydedebilirsiniz.
Robots.txt dosyasını özel olarak oluşturarak sitenizin ana dizinine eklemediğiniz durumda siteniz tüm arama motoru botlarının taramalarına açık şekilde (default) olarak yayına geçecektir.
Robots.txt Nasıl Oluşturulur, Nasıl Kullanılır?
Adından da anlaşılacağı üzere Robots dosyası txt uzantılı bir dosyadır yani herhangi bir not defteri açarak ilgili dosyayı hazırlayabilir ve sitenizin ana dizinine ekleyebilirsiniz.
Klasik bir robots.txt dosyasında olması gereken örnek bir ilk komut şu şekildedir;
Örnek 1
User-agent: *
Allow:/
Robots.txt dosyası içerisinde user-agent bölümü web robotlarını yani tarama botlarını doğrudan hedeflediğimiz bölümdür. Yani ilgili alan üzerinde hangi bota komut vermek istiyorsak o botun adını tam olarak user-agent: bölümüne yazıyoruz.
Özel olarak komut vermeyi düşündüğümüz bir bot yok ise bu bölümde * ifadesini kullanabilirsiniz. * ifadesi pek robots.txt dosyasında hepsi, tamamı anlamında kullanılır.
Örneğini verdiğimiz ifade de siteyi bütün botların tarayıp indexleyebilir olduğunu robots.txt dosyası ile ifade etmiş oluyoruz. İlgili alanda yer alan Allow komutu türkçe izin ver anlamı taşımaktadır. Yani bütün botların siteyi taramasına ve indexlemesine izin veriyorum ifadesi taşır.
Robots.txt örneklerine devam edelim;
Örnek 2
User-agent:*
Disallow:/
Bu örnek de yer alan alan user-agent komutunun ne işe yaradığını yukarıda anlatmıştık. Yukarıda verdiğimiz örneğin aksine bu ifadede arama motoru botlarının sitemizdeki hiç bir içeriği taramasını istemediğimizi ve içeriklerimizin indexlenmesini istemediğimizi Disallow komutu ile belirtmiş oluyoruz.
Disallow komutu yine allow komutu gibi robots.txt üzerinde çok sık kullanacağımız ve hangi sayfa, içerik veya url lerin taranmasını istemediğimizi belirtmekte kullanılan bir komuttur.
Yeni kurulmuş ve ayarları yapılan sitelerde hızlıca robots.txt dosyası oluşturup yukarıdaki komutu ekleyerek sitenin arama motoru botları tarafından indexlenmesini engelleyebilirsiniz. Bu sayede istemediğiniz ve ayarları tamamlanmamış sayfaların Google da görünmesini engellemiş olursunuz.
Örnek 3
User-agent: Google-bot
Disallow: /ornek-url
Bu örnekte ise yukarıda yer alan örneklerden farklı olarak doğrudan Google-bot hedeflenmiş ve ilgili botun site içerisinde yer alan içeriği taramaması gerektiği söylenmiştir.
Bu komut sonrasında Google-bot ilgili sayfa url si ile başlayan linkleri hiç bir şekilde taramayacaktır. Yani /ornek-url/2021/xxxx şeklinde devam eden bir url de yine başında Disallow: bölümünde ifade edilen url yi barındırdığı için taramalara dahil edilmeyecektir.
Örnek 4
User-agent: *
Disallow: /cgi-bin/
Disallow: /images/
Disallow: /tmp/
Disallow: /private/
Bu kullanımda yine yukarıda verdiğimiz örneklere benzer olarak web tarama botlarına aşağıda disallow formatında belirtilen 4 dosyayı taramamaları komutu verilmiştir.
Örnek 5
User-agent: *
Allow: /ornekdosya/site.html
Disallow: /ornekdosya/
Bu kullanım ise site içerisinde bir alanın botlar tarafından taranmasını istemediğiniz ancak içerisinden bir dosyanın taramalara dahil edilmesini istediğiniz durumlarda kullanılır.
Disallow komutu ile ilgili klasör taramaların dışına çıkarılırken Allow komutu ile site.html url si taramaya dahil edilir.
Özellikle komple bir klasörü taramalara kapatmak istediğinizde ancak daha sonrasında içerisinden önemli bir bölümün taranması gerektiğine karar verdiğinizde kullanılır. Bu komutun kullanımı ile alakalı siteler üzerinde sayısız senaryo mevcuttur o sebeple oldukça önemli bir kullanım olduğunu söyleyebiliriz.
Örnek 6
User-agent: ahrefsbot
Crawl-delay: 120
Bu komut çok sık kullanılmasada özellikle büyük sitelerde taramaların belirli bir düzene koyulması amacıyla kullanılır. Klasik olarak user-agent bölümüne hangi bot hedefleniyorsa o belirtilir. Biz bu örnek ahrefs.com a ait olan ahrefsbot u hedefledik.
Crawl-delay:120 komutu ile ahrefsbot’a sitemizi 120 milisaniyede bir tara yada taramalarını 120 milisaniyede bir gerçekleştir bildirimi yapılır. Buradaki süreyi isteğiniz doğrultusunda arttırabilir ve istediğiniz arama motoru botlarının sitenizi çok daha yavaş şekilde taramasını sağlayabilirsiniz.
Robots.txt Özel Direktifleri
Sitenizin büyüklüğüne göre robots.txt dosyanız üzerinden arama motoru botlarına vereceğiniz direktifler ve ihtiyaçlarınızın çeşitliliği artacaktır. Bu noktada çeşitli senaryolar için ihtiyaç duyabileceğiniz bazı özel robots.txt direktiflerine aşağıda yer vermeye çalıştık;
* Direktifleri
Üst bölümde değindiğimiz * karakteri hem user-agent noktasında hem de dizinler ile alakalı özel komutlar oluştururken kullanabileceğiniz son derece işlevli bir işaretlemedir.
Örneğin:
User-agent: Googlebot
Disallow: /*?wordfence
Robots.txt dosyanızda kullanabileceğiniz üstteki kullanım ile arama motoru botlarına url yolunda ?wordfence ifadesini (parametresini) barındıran bütün URL adreslerini ön eki ne olursa olsun tarama komutu vermiş oluyoruz. Burada ön eki ne olursa olsun ifadesinin arama motorlarına aktarılmasını sağlayan karakter * işaretlemesidir.
Özellikle * karakteri hem klasik komutların oluşturulmasında hemde belirttiğimiz gibi büyük sitelerin özellikle parametre URL adreslerini taramaya kapatırken ihtiyaç duyabileceği son derece işlevli bir robots.txt komut karakteridir.
$ Direktifi
Robots.txt üzerinde kullanabilecek özel komutlara bir diğer örnek olarak $ karakterini verebiliriz. Özellikle üstte örneğini verdiğimiz * karakterinden farklı olarak bu karakteri kullandığınızda robots.txt üzerinde belirteceğiniz herhangi bir URL yolunun ( karakter stringinin) bittiğini belirtmek için $ ifadesi kullanılır.
Örneğin:
User-agent: Yandexbot
Allow: *.webp$
Burada örneğini verdiğimiz bu komut ile Yandex’in tarama botuna, ön uzantısı ne olursa olsun dosya tipi (eki) webp olan ve yalnızca webp ile biten tüm dosyaları tarayabilirsin komutunu vermiş oluyoruz
Üstte detaylandırdığımız * ile $ kullanımı, sitelerin boyutu ne olursa olsun pek çok senaryoda ihtiyaç duyabilecek ve gerçekten robots.txt dosyanız üzerinden sitenizin taranabilirliğini sağlıklı olarak kontrol etmenize ciddi katkı sağlayabilecek özel direktiflerdir.
Burada webp üzerinden örneğini verdiğimiz şekilde siz kendi site yapınıza uygun olarak pdf dosyalarını, xls dosyalarını xml leri ve sayısız daha pek çok farklı dosya tipini siteniz üzerinden taramaya kapatabilir yada taramalara açabilirsiniz.
Robots.txt Dosyanıza Site Haritası Ekleyin
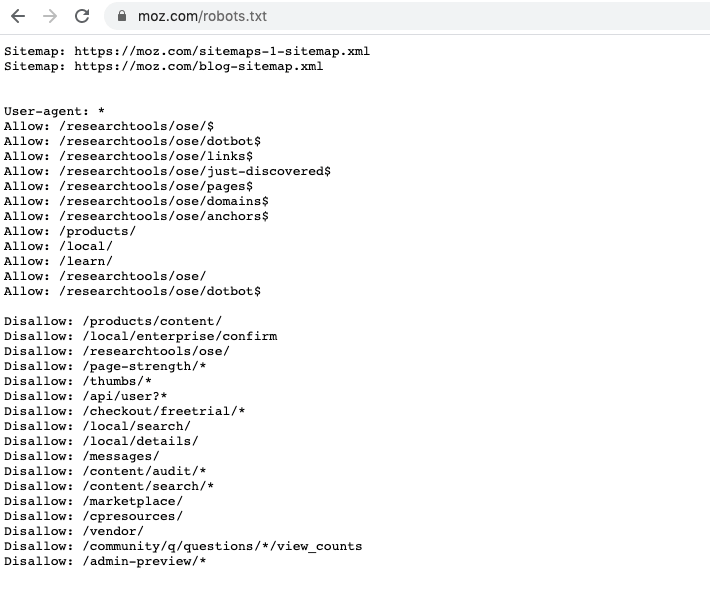
SEO dostu robots txt dosyası için önemli olan bir diğer komutta manuel olarak veya programlar vasıtasıyla oluşturduğunuz site haritasının sitemap: komutu ile eklenmesidir. Pek çok web sitesi robots.txt dosyasında düzenlemeleri doğru yapsa da bu küçük ama önemli detayı atlamakta ve sitenin arama motorları tarafından çok daha hızlı taranması fırsatını kaçırmaktadır.
Robots.txt dosyasında izin verdiğiniz ve engellediğiniz alanları belirttikten sonra yapmanız gereken işlem, sitenizde oluşturduğunuz sitemap url sini robots txt ye eklemektir.
User-agent:*
Allow:/
Sitemap: https://www.dijitalzade.com/sitemap_index.xml
Örnek bir ideal robots.txt kullanımı bu şekilde olmalıdır. Siz sitenize göre ve isteğiniz doğrultusunda üstte yer alan allow ve disallow bölümünü oluşturmayı unutmayın.
Üstte yer alan görselde moz.com tarafından oluşturulan ideal bir robots.txt dosyasını görebilirsiniz.
Sonuç
Robots.txt bütün web yöneticilerinin muhakkak bir defada olsa duyduğu ancak çoğu zaman site sahipleri tarafından atlanan son derece önemli bir dosyadır. Özellikle SEO çalışmalarında sonuç elde etmek isteyen web yöneticileri sitenin taranabilirliğini önemli ölçüde kontrol eden ve arama motoru botlarını kontrol etmeye imkan tanıyan bu dosyayı mutlaka kullanmalıdır.
Bizde bu yazımızda Robots txt dosyasının ne olduğundan ve nasıl kullanıldığından detaylı olarak bahsetmeye çalıştık. Yukarıda verdiğimiz örnekler ideal bir Robots txt dosyası oluştururken ihtiyaç duyabileceğiniz ve her çeşit robots.txt yi oluşturmada kullanabileceğiniz ideal kullanımlardır.



